
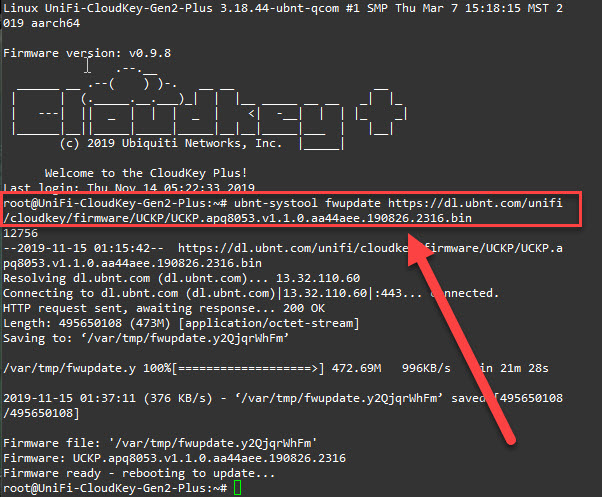
Critical Zero-Click Outlook RCE: CVE-2026-40361 Demands Immediate Patching
A zero-click remote code execution vulnerability in Microsoft Outlook (CVE-2026-40361) allows attackers to compromise any Outlook user by simply sending a crafted email — no clicks required. Patched in Microsoft's May 2026 Patch Tuesday update, this CVSS 8.4 flaw affects all supported Office and Microsoft 365 Apps versions. SMBs must patch immediately.


















Recent Comments